



AI models depend on vectors to understand text, images, or data directly. More specifically, they rely on high-dimensional vectors that encode semantic meaning. It allows the system to capture and process complex information, such as features of an image or properties of datasets.
While these vectors are powerful, they also consume vast amounts of memory. This means more bottlenecks in the key value cache – the model’s short-term memory used for quick response without needing to recompute every time.
To address this issue, researchers have long used vector quantization, a compression technique that reduces the size of high-dimensional vectors. This optimizes two critical factors for AI – enhanced vector search and unclogged key value cache bottleneck. However, this method introduces additional memory overhead. That partially defeats the purpose of vector quantization.
TurboQuant demonstrates robust KV cache compression performance across the LongBench benchmark relative to various compression methods on the Llama-3.1-8B-Instruct model (bitwidths are indicated in brackets). Source: Google
Google has introduced TurboQuant to overcome this challenge. It is a software-based AI memory compression technology for large language models and vector search engines. According to Google, this compression method reduces memory usage by roughly 6x, while accelerating attention computation by up to 8x – all without any loss of accuracy.
What this means is that systems can serve more users per GPU, respond faster, and support longer context windows without requiring additional hardware. This may lead to less demand for memory in future inference applications. TurboQuant is set to be presented at the ICLR 2026 later this month in Rio de Janeiro, Brazil.
TurboQuant works by combining two complementary techniques to achieve what it claims as “high reduction in model size with zero accuracy loss”. The first technique is high-quality compression, what Google calls the PolarQuant method. It works by randomly rotating the data vectors to simplify the data’s geometry. This makes it easier to apply a high-quality quantizer to each part of the vector individually.
After most of the compression power is used to capture the main concept and strength of the original vector, the next technique is to eliminate the hidden errors. TurboQuant achieves this by using the residual amount of compression power (roughly 1 bit) to apply the QJL algorithm – a mathematical technique that preserves relationships between compressed vectors.
The QJL stage acts as a way to eliminate bias, leading to a more accurate attention score. “This algorithm essentially creates a high-speed shorthand that requires zero memory overhead,” shared Google in a blog introducing TurboQuant.

TurboQuant illustrates a substantial performance increase in computing attention logits within the key-value cache across various bit-width levels, measured relative to the highly optimized JAX baseline. Source: Google
“To maintain accuracy, QJL uses a special estimator that strategically balances a high-precision query with the low-precision, simplified data. This allows the model to accurately calculate the attention score (the process used to decide which parts of its input are important and which parts can be safely ignored).”
PolarQuant is critical to the success of this system. It essentially acts like a high-efficiency compression bridge, converting Cartesian inputs into an easier to store and process Polar “shorthand”. It begins by pairing up values from the vector and expressing each pair in polar form. These are then grouped and transformed again in successive rounds, gradually simplifying the data until it can be represented as one final magnitude and a series of angles that capture its key characteristics.
Google shared experiments and results using TurboQuant. This includes testing across various long-context benchmarks, such as ZeroSCROLLS, LongBench, Needle in a Haystack, RULER, and L-Eval.
Based on the results, TurboQuant consistently maintained accuracy while significantly reducing memory usage. This included tasks such as summarization and code generation. It was also put through a Needle in a Haystack test where it had to retrieve a single and tiny detail from a large context. TurboQuant preserved near perfect accuracy under heavy compression during the test.
The results were also impressive from a systems perspective. TurboQuant reduces memory bandwidth pressure and improves cache residency by compressing cache precision from 16 bit to around 3 bit. This allows the 8x faster attention computation on H100 GPUs. In vector search evaluations, it also achieves higher recall ratios than baseline methods.

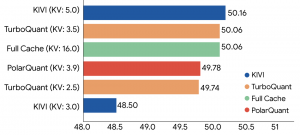
TurboQuant demonstrates robust retrieval performance, achieving the optimal 1@k recall ratio on the GloVe dataset (d=200) relative to various state-of-the-art quantization baselines. Source: Google
The results show TurboQuant goes beyond just improving compression – it addresses a critical constraint: memory bandwidth. It cuts down both the memory footprint and the amount of data that needs to move. This is a turning point for how AI scales, especially as efficiency is increasingly becoming as important as raw compute itself.
As models continue to grow in size and context, the ability to reduce memory pressure without sacrificing accuracy may prove just as important as advances in model architecture or hardware. The real test will be whether these gains hold up under real world workloads and integration constraints. However, if Google’s claims hold in production, it could be a turning point in AI evolution. And TurboQuant could play a central role in scaling AI systems more efficiently.
If you want to read more stories like this and stay ahead of the curve in data and AI, subscribe to BigDataWire and follow us on LinkedIn. We deliver the insights, reporting, and breakthroughs that define the next era of technology.
The post Google’s TurboQuant Marks a Fundamental Shift in How AI Systems Scale appeared first on BigDATAwire.
Go to Source
Author: Ali Azhar



