In user-facing distributed systems, latency is often a stronger signal of failure than errors. When responses exceed user expectations, the distinction between “slow” and “down” becomes largely irrelevant, even if every service is technically healthy.
I’ve seen this pattern across multiple systems. One incident, in particular, forced me to confront how much production behavior is shaped by defaults we never explicitly choose. What stood out was not the slowness itself, but how “infinite by default” waiting quietly drained capacity long before anything crossed a traditional failure threshold.
Details are generalized to avoid sharing proprietary information.
When slowness turned into an outage
The incident started with support tickets, not alarms. Early in the morning, they began to appear:
- Product pages don’t load.
- Checkout is stuck.
- The site is slow today.
At the same time, our dashboards drifted in subtle ways. CPU climbed, memory pressure increased and thread pools filled while error rates stayed low. Product pages began hanging intermittently: some requests completed, others stalled long enough that users refreshed, opened new tabs and eventually left.
I was on call that week. There had been a recent deployment, so I rolled it back early. It had no effect, which told us the issue wasn’t a specific change, but how the system behaved under sustained slowness.
Within a few hours, the impact was measurable. Product page abandonment increased sharply. Conversion dropped by double digits. Support ticket volume spiked. Users started switching to competitors. By the end of the day, the incident resulted in a six-figure loss and, more importantly, a visible loss of user trust.
The harder question wasn’t what failed, but why user impact appeared before our pages fired. The system crossed the user’s pain threshold long before it crossed any paging threshold. Our alerts were optimized for hard failures – errors, instance health, explicit saturation – while latency lived on dashboards rather than in paging.
The failure mode we missed
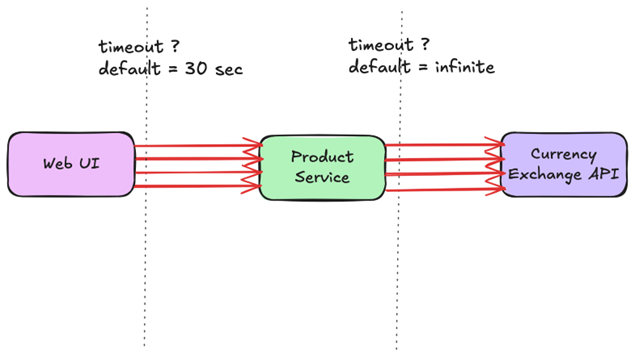
Product pages displayed prices in the user’s local currency. To do that, the Product Service called a downstream currency exchange API. That dependency did not go down. It became slow, intermittently, for long enough to trigger a cascade.
As I dug deeper during the incident, one detail stood out. The Product Service used an HTTP client with default configuration, where the request timeout was effectively infinite. On the frontend, browsers stopped waiting after roughly 30 seconds. On the backend, requests continued to wait long after the user had already given up.
Violetta Pidvolotska
That gap mattered more than I expected. The first few hung currency calls held onto Product Service worker threads and outbound connections, so new requests began queuing behind work that no longer had a user on the other end. Once the shared pools started to saturate, it stopped being “only the currency path.” Even requests that didn’t require currency conversion slowed down because they waited for the same thread pool and the same internal capacity.
At that point, the dependency didn’t need to fail to take the service down. It only needed to become slow while we kept waiting without a boundary. This wasn’t an error failure. It was a capacity failure. Blocked concurrency accumulated faster than it could drain, latency propagated outward and throughput collapsed without a single exception being thrown.
Some mitigations helped only temporarily. Restarting instances or shedding traffic reduced pressure for a short time, but the relief never lasted. As long as requests were allowed to wait indefinitely, the system kept accumulating work faster than it could complete it.
When we finally pinpointed the unbounded wait, the immediate fix sounded simple: set a timeout. The real lesson was deeper.
Defaults that quietly shape system behavior
At first glance, this looked like a simple misconfiguration. In reality, it reflected how common default settings influence system behavior in production.
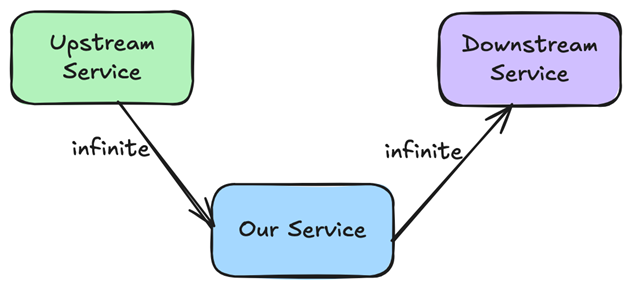
Many widely used libraries and systems default to infinite or extremely large timeouts. In Java, common HTTP clients treat a timeout of zero as “wait indefinitely” unless explicitly configured. In Python, requests will wait indefinitely unless a timeout is set explicitly. The Fetch API does not define a built-in timeout at all.
These defaults aren’t careless. They’re intentionally generic. Libraries optimize for the correctness of a single request because they can’t know what “too slow” means for your system. Survivability under partial failure is left to the application.
Production systems rarely fail under ideal conditions. They fail under load, partial outages, retries and real user behavior. In those conditions, unbounded waiting becomes dangerous. Defaults that feel harmless during development quietly make architectural decisions in production.
When we later audited our services as a team, we found that many calls either had no timeouts or had values that no longer matched real production latency. The defaults had been shaping system behavior for years, without us explicitly choosing them.
The mental model behind long timeouts
What this incident revealed wasn’t just a missing timeout. It exposed a mental model many teams rely on, including ours at the time.
That model assumes:
- Dependencies are usually fast
- Slowness is rare
- Defaults are reasonable
- Waiting longer increases the chance of success
It prioritizes individual request success, often at the cost of overall system reliability. As a result, teams often don’t know their effective timeouts, different services use inconsistent values and some calls have no timeouts at all.
Violetta Pidvolotska
Even when timeouts exist, they are often far longer than what user behavior justifies. In our case, users retried within a few seconds and abandoned within about ten. Waiting beyond that didn’t improve outcomes. It only consumed capacity.
Long timeouts can also mask deeper design problems. If a request regularly times out because it returns thousands of items, the issue isn’t the timeout itself. It’s missing pagination or poor request shaping. By optimizing for individual request success, teams unintentionally trade away system-level resilience.
Timeouts as failure boundaries
Before this incident, we mostly treated timeouts as configuration knobs. After that, we started treating them as failure boundaries.
A timeout defines where a failure is allowed to stop. Without timeouts, a single slow dependency can quietly consume threads, connections and memory across the system. With well-chosen timeouts, slowness stays contained instead of spreading into a system-wide failure.
We made a set of deliberate changes:
1. Enforced timeouts on the client side
The caller decides when to stop waiting. Load balancers, proxies or servers could not reliably protect us from hanging forever, as the incident made clear.
2. Introduced explicit end-to-end deadlines for user-facing flows
Downstream calls could only use the remaining time budget; waiting beyond that point was wasted work with no chance of improving the outcome.
Violetta Pidvolotska
We made those deadlines explicit and portable. In HTTP flows, we propagated an end-to-end deadline via a single X-Request-Deadline header so each service could compute the remaining time and set per-call timeouts accordingly. We chose a deadline (not a per-hop timeout) because it composes cleanly across service boundaries and retries.
For gRPC paths, built-in deadlines allowed remaining time to propagate across service boundaries. We extended that same boundary through internal request context so background work stopped when the budget did.
3. Became deliberate about how timeout values were chosen
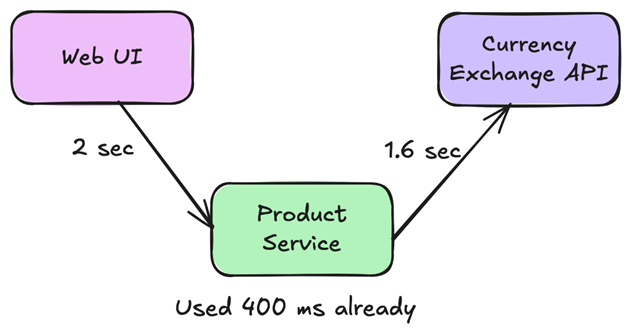
Connection timeouts were kept short and tied to network behavior. Request timeouts were based on real production latency, not intuition.
Rather than relying on averages, we focused on p99 and p99.9. When p50 was close to p99, we left room so minor slowdowns didn’t amplify into timeout spikes. This helped us understand how slow requests behaved under load and choose timeouts that protected capacity without causing unnecessary failures.
For example, if 99% of requests completed in 300 milliseconds, a timeout of 350-400 milliseconds provided a better balance than tens of seconds. What happened beyond that point became a conscious product decision. In our case, when currency conversion timed out, we fell back to showing prices in the primary currency. Users consistently preferred an imperfect answer over waiting indefinitely.
We also kept retries conservative in user-facing paths. A retry that doesn’t respect an end-to-end deadline is worse than no retry: it multiplies work after the user has already moved on. That’s how “helpful” retries turn into retry storms under partial slowness.
As a team, we codified these decisions into shared client defaults and a mandatory review checklist used across new and existing call paths so unbounded waiting didn’t quietly return.
Keeping timeouts honest
Timeouts should never be silent. After the incident, we focused on three things:
1. Making timeouts observable
Every timeout emitted a structured log entry with dependency context and remaining time budget. We tracked timeout rates as metrics and alerted on sustained increases rather than individual spikes. Rising timeout rates became an early warning signal instead of a surprise during incidents. Importantly, we updated paging to include user-impacting latency and “requests not finishing” signals, not just error rate.
2. Stopping the treatment of timeout values as constants
Traffic grows, dependencies change and architectures evolve, so values that were reasonable a year ago are often wrong today. We reviewed timeout configuration whenever traffic patterns shifted, new dependencies were introduced or latency distributions changed.
3. Validating timeout behavior before real incidents forced the issue
Introducing artificial latency in non-production environments quickly exposed hanging calls, retry amplification and missing fallbacks. It also forced us to separate two different questions: what breaks under load and what breaks under slowness.
Traditional load tests answered the first. Fault-injection and latency experiments revealed the second, a form of controlled failure often described as chaos engineering. By introducing controlled delay and occasional hangs, we verified that deadlines actually stopped work, queues didn’t grow without bound and fallbacks behaved as intended.
Lessons that carried forward
This incident permanently changed how I think about timeouts.
A timeout is a decision about value. Past a certain point, waiting longer does not improve user experience. It increases the amount of wasted work a system performs after the user has already left.
A timeout is also a decision about containment. Without bounded waits, partial failures turn into system-wide failures through resource exhaustion: blocked threads, saturated pools, growing queues and cascading latency.
If there is one takeaway from this story, it is this: define timeouts deliberately and tie them to budgets. Start from user behavior. Measure latency at p99, not just averages. Make timeouts observable and decide explicitly what happens when they fire. Isolate capacity so that a single slow dependency cannot drain the system.
Unbounded waiting is not neutral. It has a real reliability cost. If you do not bound waiting deliberately, it will eventually bound your system for you.
This article is published as part of the Foundry Expert Contributor Network.
Want to join?
Go to Source
Author: