





Since its initial release in 2011, Apache Kafka has cemented itself as the de facto platform for event streaming. Kafka enthusiast Tim Berglund often refers to it as the “universal data substrate.” This is made possible in large part by the Kafka ecosystem that enables connectivity between Kafka and external systems (Kafka Connect) and a Java stream processing library (Kafka Streams).
The latest release of Apache Kafka delivers the queue-like consumption semantics of point-to-point messaging. After many hours of development and testing in recent releases, this feature is generally available in Kafka 4.2.
Let’s start with a quick “compare-and-contrast” of event streaming and message queuing. Event streaming is for high-volume, real-time processing of an unbounded, continuous stream of data, and it allows for consumers to replay old events as needed. Consumer applications record the offset (the ordinal position in each topic partition) of the last event Kafka successfully processed. If a consumer terminates or restarts, it’s able to resume processing the assigned partition from the last committed offset. Example use cases include internet ad attribution, updating ride-share status, and monitoring for credit card fraud. This is the space where Kafka has thrived, with adoption by over 80% of all Fortune 100 companies.
Message queues are used for point-to-point communication, where a message is typically consumed once and removed from the queue. Unlike with event streaming, consuming applications are able to acknowledge each message. This messaging pattern decouples applications and services via guaranteed, one-time processing for tasks such as in-app notifications to mobile devices, generating payroll records, or calling an AI model. Popular platforms in this space include RabbitMQ, ActiveMQ, and IBM MQ.
These message queue use cases have been a “square peg in a round hole” for Apache Kafka. Why? For starters, scaling the “traditional” Kafka consumer group is constrained by the number of topic partitions. Most notably, Kafka consumers don’t have message-level acknowledgement semantics. These features enable consumers’ message queue systems to cooperatively operate on messages in a queue.
This is the major motivation behind KIP-932: Queues for Kafka. Let’s see how this Kafka implementation of message queuing could be an important tool in your event-driven architecture.
Scaling Kafka consumer applications
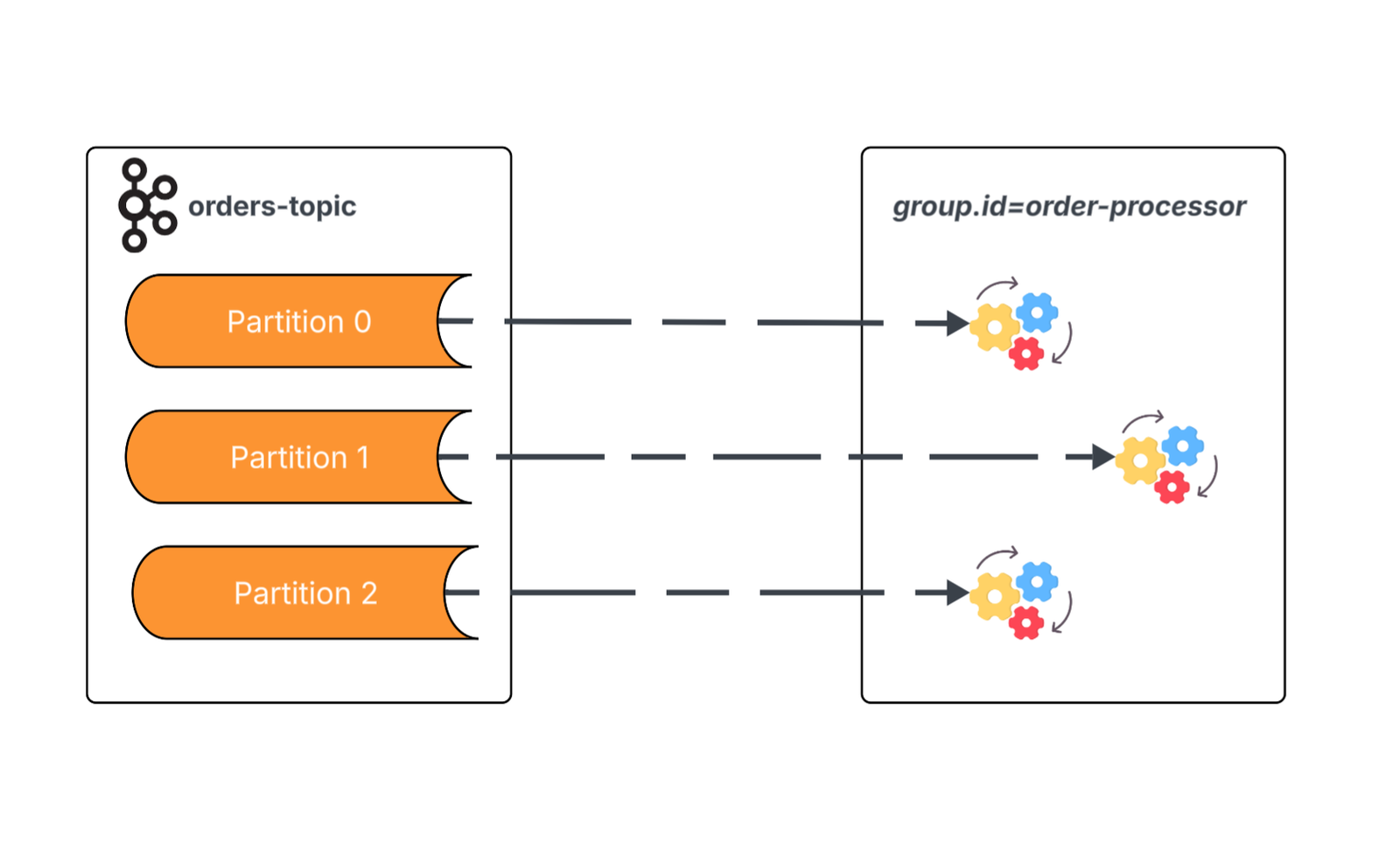
Traditionally, parallel processing of Kafka topic data is constrained by the number of partitions of the topic being consumed. The broker assigns consumption of each partition of the topic to a single member of a consumer group. Once the membership of the consumer group equals the partitions of the topic, any new consumers added to the group will be idle.
This diagram illustrates three instances in a consumer group subscribed to a topic with three partitions — meaning we’ve maxed out our parallel processing potential for this topic.
Confluent
KIP-932 adds a new type of group called a share group. Nothing changes about how the data is written to Kafka by producer applications or how data is stored in Kafka. Your event streaming use cases can operate on the same topics.
Share groups introduce a new cooperative consumption model, where consumers in a share group work in a similar fashion to consumers/subscribers in message queuing systems. On the broker, each topic-partition has a corresponding share partition which tracks the lifecycle of each message in relation to the share group. This allows the share consumers to be scaled beyond the number of topic partitions.
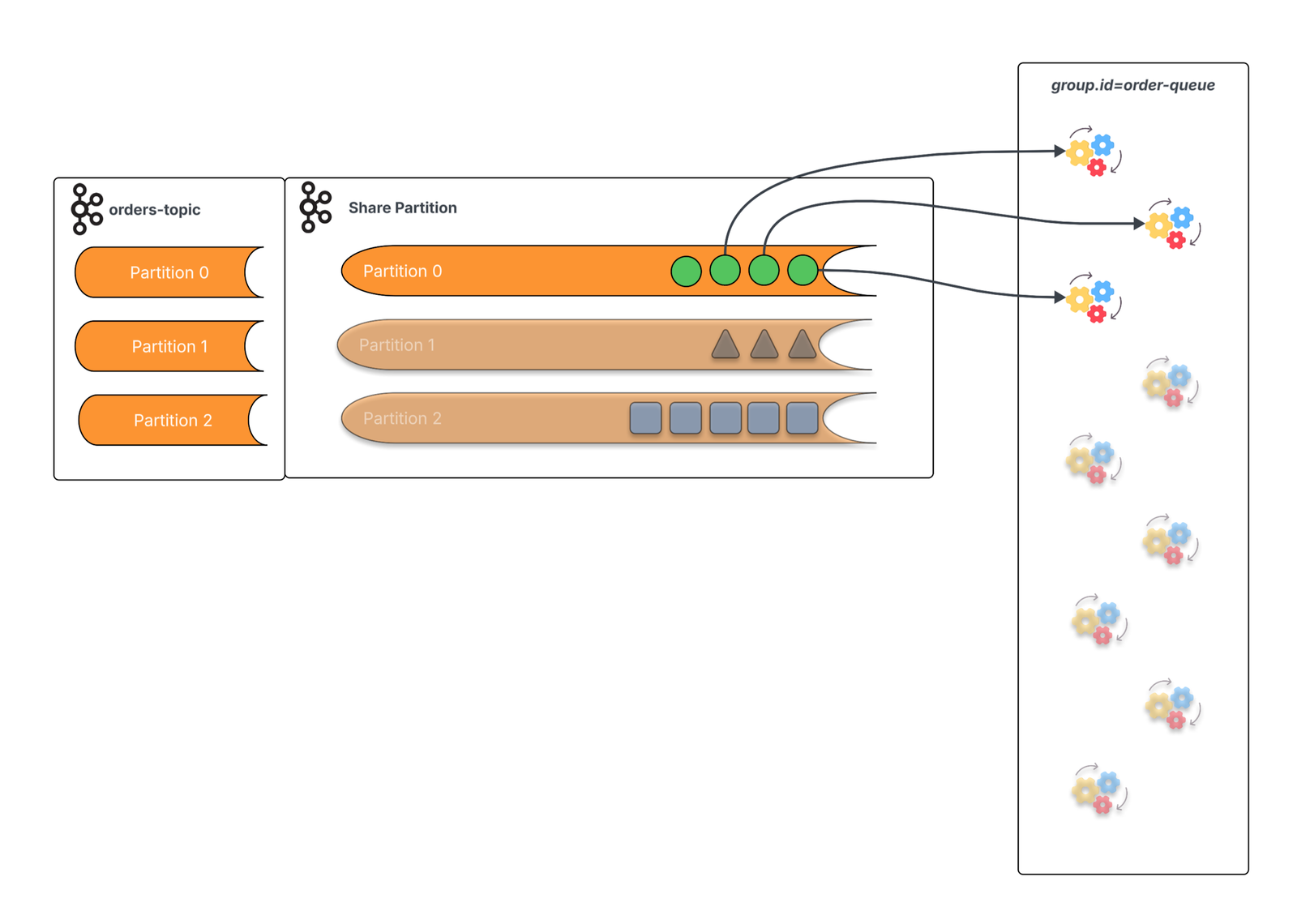
This diagram depicts the new cooperative consumption model — where multiple members of the consumer group process data from a single topic partition.
Confluent
This cooperative consumption from a topic partition also means we lose the partition-level processing order guarantees of the “traditional” Kafka consumer. That’s the trade-off for this scaling, but cooperative consumption also is intended for use cases where throughput and scaling take precedence over the order of processing.
Message-level acknowledgement
The APIs for KIP-932 should be familiar to developers who are already using Kafka. For starters, nothing changes about how events are produced to Kafka topics. On the consumer side, the KafkaShareConsumer interface is very similar to the existing KafkaConsumer. Consumer applications will poll for available messages and process each resulting ConsumerRecord instance.
The consumers now have the ability to acknowledge the delivery of each record on an individual basis. By default, every message is implicitly acknowledged as successfully processed. However, there are scenarios where the developer needs more fine-grained controls, particularly around error handling and long-running tasks.
By using the value of explicit for the consumer configuration’s share.acknowledgement.mode, the code takes on the responsibility of specifying how each message should be acknowledged. The available AcknowledgementType values are ACCEPT, RELEASE, REJECT, and RENEW. These values influence the state of each message in relation to the share group. Those states are AVAILABLE, ACQUIRED, ACKNOWLEDGED, and ARCHIVED.
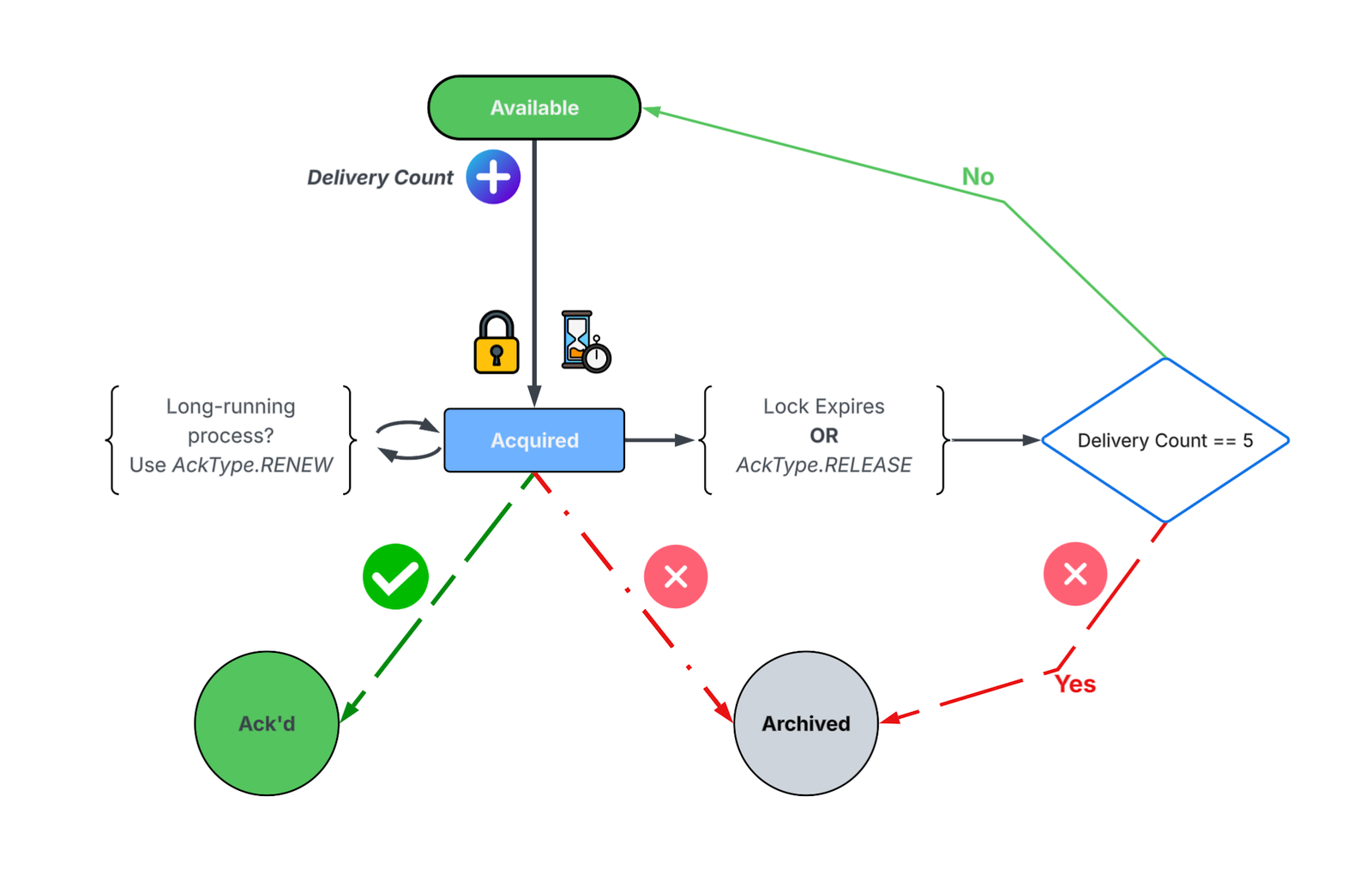
The state machine that controls the life cycle of messages based on these acknowledgement types is detailed in this diagram.
Confluent
Only messages in an AVAILABLE state can be fetched by a consumer. When fetched, a message transitions to the ACQUIRED state and a delivery count for that message is incremented. This effectively “locks” this message from fetches by other members of the share group.
Once ACQUIRED, a message is expected to be processed in a finite amount of time. If this “lock” or “lease” expires, the message is either sent back to the ACQUIRED state or moved to an ARCHIVED state, based on the delivery count of the message. The state and delivery count of each message is tracked in the share partition. This provides for a built-in retry mechanism developers can use in the event of a condition where the message process could be reattempted, as the message could be acknowledged using the RELEASE type.
If message processing completes successfully, that message is acknowledged with the ACCEPT type. This transitions the message to the ACKNOWLEDGED state.
There are cases where processing takes a non-deterministic amount of time. Perhaps the consumer calls a third-party or partner API. Maybe it’s augmenting the message with the result of an LLM call. These aren’t “failures,” and the processing code may need more time to complete. In this case, acknowledge the message with the RENEW type to reset the lock.
Unifying messaging protocols and infrastructure
Many organizations have both event streaming and message queuing use cases. This often means operators are maintaining and supporting Apache Kafka and an older message queuing system. Developers integrate applications with different messaging libraries and protocols in the same application code base. All of this happens as the C-suite is asking why we’re paying for multiple messaging solutions.
Consolidating these messaging use cases onto Apache Kafka will make producing applications simpler to develop, deploy, upgrade, and maintain. It will also help consumer applications scale to meet the needs and SLAs of the messages being processed.
Unlike traditional message queue systems, events in these “queues” enjoy the durability and storage guarantees we’ve come to rely on in Apache Kafka. Developers of consumer applications determine if the events should be processed as event streams or queues.
Operators and SREs (site reliability engineers) tend to like simplicity. (That could be due to the correlation between simplicity and the number of production incidents.) Unifying these messaging platforms means fewer systems to configure, deploy and patch. And that also addresses the concerns of the C-suite — lowering the total cost of ownership for the overall application infrastructure.
What queues for Kafka means for teams
KIP-932 brings long-awaited point-to-point semantics to Apache Kafka. This implementation layers queue-like consumption and message-level acknowledgment onto the durability, scalability, and throughput that have made Kafka mission-critical infrastructure for businesses from startups to large enterprises.
For development teams, this means writing applications against a single messaging API rather than juggling multiple protocols. For operations teams, it means consolidating infrastructure and reducing complexity. And for organizations, it means lower total cost of ownership without sacrificing the specific semantics each use case requires.
KIP-932 is available in Apache Kafka 4.2 and Confluent Cloud, with support coming to Confluent Platform version 8.2. Developers can explore the implementation and start testing queue-based consumption patterns now. For more about KIP-932 and other event streaming topics, visit Confluent Developer for free learning resources curated by our team of experts.
—
New Tech Forum provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to doug_dineley@foundryco.com.
Go to Source
Author:



