



If you came up building software in the 1990s or early 2000s, you remember the visceral satisfaction of determinism. You wrote code. The compiler analyzed it, optimized it, and emitted precisely the machine instructions you expected. Same input, same output. Every single time. There was an engineering rigor to it that shaped how an entire generation of developers thought about building systems.
Then large language models (LLMs) arrived and, almost overnight, code generation became a stochastic process. Prompt an AI model twice with identical inputs and you’ll get structurally different outputs—sometimes brilliant, sometimes subtly broken, occasionally hallucinated beyond repair. For quick prototyping that’s fine. For enterprise-grade software—the kind where a misplaced null check costs you a production outage at 2am—it’s a non-starter.
We stared at this problem for a while. And then something clicked. It felt familiar, like a pattern we’d encountered before, buried somewhere in our CS fundamentals. Then it hit us: the two-pass compiler.
A quick refresher
Early compilers were single-pass: read source, emit machine code, hope for the best. They were fast but brittle—limited optimization, poor error handling, fragile output. The industry’s answer was the multi-pass compiler, and it fundamentally changed how we build languages. The first pass analyzes, parses, and produces an intermediate representation (IR). The second pass optimizes and generates the final target code. This separation of concerns is what gave us C, C++, Java—and frankly, modern software engineering as we know it.
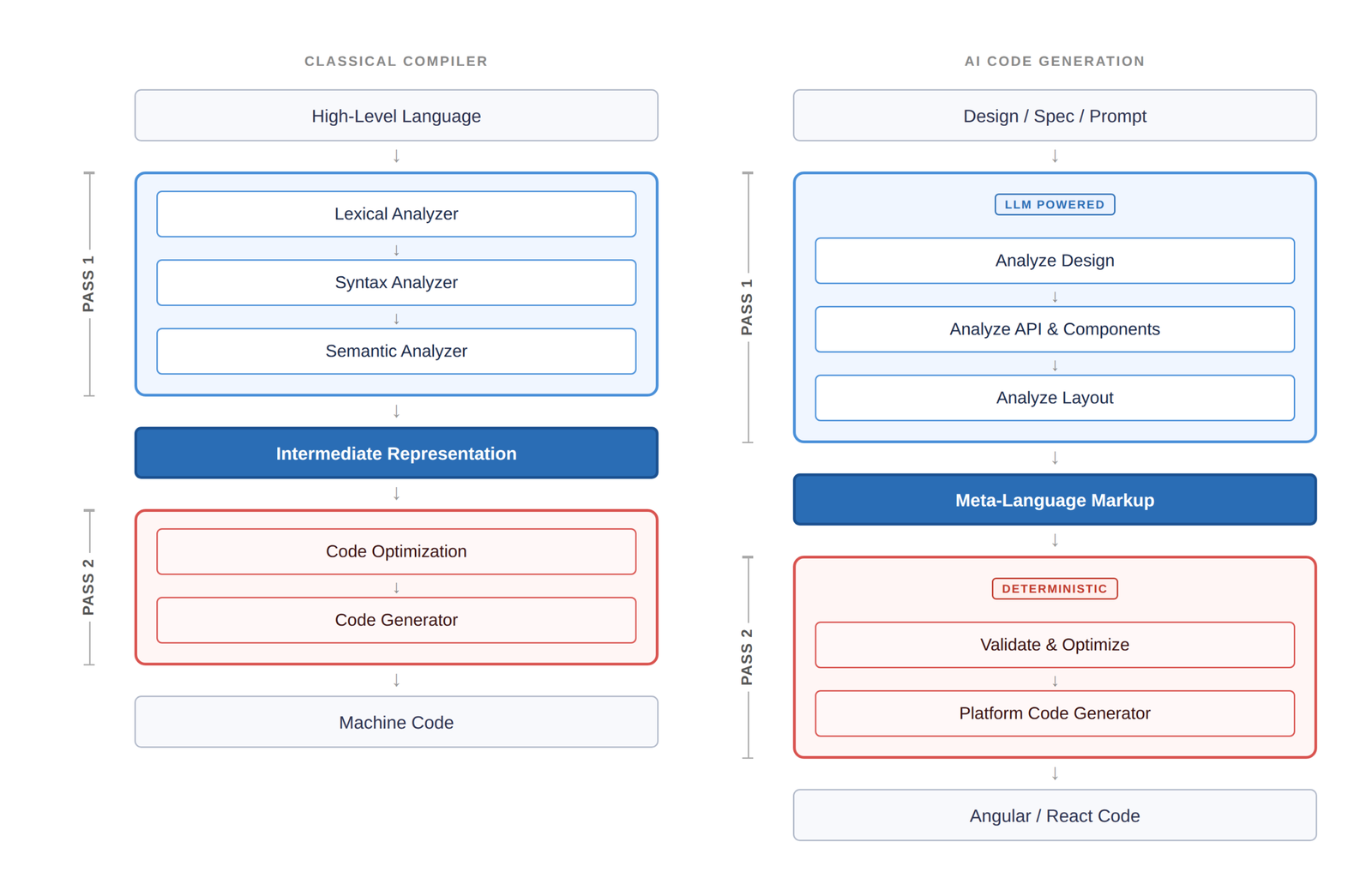
The structural parallel between classical two-pass compilation and AI-driven code generation.
WaveMaker
The analogy to AI code generation is almost eerily direct. Today’s LLM-based tools are, architecturally, single-pass compilers. You feed in a prompt, the model generates code, and you get whatever comes out the other end. The quality ceiling is the model itself. There’s no intermediate analysis, no optimization pass, no structural validation. It’s 1970s compiler design with 2020s marketing.
Applying the two-pass model to AI code generation
Here’s where it gets interesting. What if, instead of asking an LLM to go from prompt to production code in one shot, you split the process into two architecturally distinct passes—just like the compilers that built our industry?
Pass 1 is where the LLM does what LLMs are genuinely good at: understanding intent, decomposing design, and reasoning about structure. The model analyzes the design spec, identifies components, maps APIs, resolves layout semantics—and emits an intermediate representation, an IR. Not HTML. Not Angular or React. A well-defined meta-language markup that captures what needs to be built without committing to how.
This is critical. By constraining the LLM’s output to a structured meta-language rather than raw framework code, you eliminate entire categories of failure. The model can’t inject malformed tags if it’s not emitting HTML. It can’t hallucinate nonexistent React hooks if it’s outputting component descriptors. You’ve reduced the stochastic surface area dramatically.
Pass 2 is entirely deterministic. A platform-level code generator—no LLM involved—takes that validated intermediate markup and emits production-grade Angular, React, or React Native code. This is the pass that plugs in battle-tested libraries, enforces security patterns, and applies framework-specific optimizations. Same IR in, same code out. Every time.
First pass gives you speed. Second pass gives you reliability. The separation of concerns is what makes it work.
Why this matters now
The advantages of this architecture compound in exactly the ways that matter for enterprise development. The meta-language IR becomes your durable context for iterative development—you’re not re-prompting the LLM from scratch every time you refine a component. Security concerns like script injection and SQL injection are structurally eliminated, not patched after the fact. Hallucinated properties and tokens get caught and stripped at the IR boundary before they ever reach generated code. And because Pass 2 is deterministic, you get reproducible, auditable, deployable output.
| Pass 1 — LLM-powered
• Translates design/spec to structured components and design tokens Eliminates script/SQL injection by design |
Pass 2 — Deterministic
• Generates optimized, secure, performant framework code Plugs in battle-tested libraries for reliability |
If you’ve spent your career building systems where correctness isn’t optional, this should resonate. The industry spent decades learning that single-pass compilation couldn’t produce reliable software at scale. The two-pass architecture wasn’t just an optimization, but an engineering philosophy: separate understanding from generation, validate before you emit, and never let a single phase carry the entire burden of correctness.
We’re at the same inflection point with AI code generation right now. The models are powerful. The architecture around them has been naive. The fix isn’t to wait for a smarter model. It’s to apply the engineering discipline we’ve always known, and build systems where stochastic brilliance and deterministic reliability each do what they do best—in the right pass, at the right time.
Deterministic software engineering is cool again. Turns out it never really left.
—
New Tech Forum provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to doug_dineley@foundryco.com.
Go to Source
Author:

