GPUs are still important for Nvidia, which held its GPU Technology Conference (GTC) last week in San Jose. But the importance of GPUs appears to be waning as the AI boom is creating a surge in demand for general purpose CPUs and other processor types that offer advantages for AI inference. Nvidia wants to control this emerging market too, as CEO Jensen Huang, AKA the “Inference King,” made clear in his keynote.
Forget about Nvidia as the GPU company. “Most people forget that Nvidia’s business is much, much more diversified than a chip company,” Huang said during a Q&A with the press at GPC last week. “And the reason for that is because we’re full stack and we can help people build AI factories anywhere.”
If a company spends $30 billion to build an AI factory to generate tokens, they will want to equip it with chips that can generate tokens at efficiently as possible. That is Nvidia’s goal: to help customers build systems to generate a huge amount of tokens as affordably as they can.
“Inference is your workload and tokens is your new commodity,” Huang said in his keynote. “That compute is your revenues, [and] you want to make sure that the architecture is as optimized as you can in the future. Every single CSP, every single computer company, every single cloud company, every single AI company, every single company period, is going to be thinking about their token factory effectiveness.”
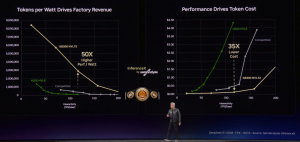
Nvidia is already leading the AI inference ballgame. Dylan Patel of the benchmarking company SemiAnalysis has run the numbers, and he found GB300 delivered not a 35x increase in performance per watt versus Hopper, but 50x. That led SemiAnalysis to name Nvidia the Inference King, a name that Huang instantly latched onto.
SemiAnalysis named Nvidia NVL72 the Inference King thanks to its leadership in token generation efficiency
As part of that full stack, Nvidia is focusing on lowering the cost of delivering AI inference at massive scale. That is in line with a new prediction from Gartner, which today forecast that the cost of an AI inference token will drop by 90% by 2030. Judging by what Nvidia presented at GTC, it is planning to match this figure.
A Platform for AI Inference
GPUs still play a critical role in Nvidia’s Vera Rubin platform, but it’s not the big player that it was when the generative AI revolution really started to get going back in 2023. As part of the Vera Rubin architecture, Nvidia is offering five specialized systems, all based on its liquid-cooled MGX rack architecture, which it fills with these chips.
There is, of course, the NVL72, which features 36 Vera Rubin superchips connected with an NVLink switch. But in addition to that longstanding system, Nvidia is offering several more, which it dubs the MGX ETL line. The MGX ETL line includes:
- Groq 3 LPX, which features 256 Groq 3 language processing unit (LPU), connected with Groq’s chip-to-chip interconnect;
- Vera CPU Rack, which features 256 Vera CPUs linked with a SpectrumX Ethernet interconnect;
- BlueField-4 STX, a storage rack filled with 72 Bluefield-4 data processing unit (DPU), connected with SpectrumX Ethernet interconnect, which forms the basis for its new context memory storage (CMX) platform;
- and Spectrum-6 SPX rack, which can be loaded with either Spectrum-X Ethernet or NVIDIA Quantum-X800 InfiniBand switches to provide north-south and east-west connectivity within a data center.
“The new Vera Rubin platform: seven chips, five rack-scale computers, one revolutionary AI supercomputer for agentic AI,” Haung said during his keynote address at GTC 2026 last week. “Forty million times more compute in just 10 years.”
Prefill and Decode
GPUs are instrumental for AI model training, and they’re also needed in the first stage of AI inference, called prefill, when the prompt is received and input into the AI model. But GPUs are not as efficient at running the second stage of AI inference, the decode stage, which is where the AI model generates responses to the prompt.
During the decode stage, the AI model generates tokens one at a time based on the current prompt and other previous prompts, which are stored in the KV cache, a critical element in the modern AI inference workflow. The bottleneck during the decode stage is the speed at which data can be moved from memory to the processor, not the speed of the processor, which is the GPU’s biggest advantage. While GPUs have large amounts of high-bandwidth memory and can be used for decode, it’s not an efficient use of the GPU, and that inefficiency spells trouble in a $30 billion gigawatt AI factory.

Six months ago, Nvidia introduced a version of the Rubin GPU that was better at AI inference, dubbed the CPX. But Groq seems to have replaced it, and the CPX will not be delivered in 2026, as previously planned, the company said.
Nvidia wants its AI factory customers to use other chip types to accelerate various parts of AI acceleration. CPUs, like the new Vera ARM chip, will be used to run a variety of different workloads during AI inference, while LPUs like Groq 3 are specialized to handle specific parts of the decode phase, including pulling data from the KV cache. Other chips, like the BlueField-4 DPUs and Spectrum-X SuperNICs, will be instrumental in getting data to and from storage in the quickest amount of time, and potentially avoiding the dreaded GPU memory wall.
Vera, a ‘Cool’ CPU
The AI boom has moved processing demand back over the CPU sweet spot, which led executives at AMD and Intel to declare that CPUs are “cool again.” You could say that Nvidia got the message, too.
Nvidia rolled out its new Vera CPU at GTC 2026. The 88-core ARM chip boasts some impressive stats against its X86 rivals, including 1.5x the “sandbox performance” (or running compilers, runtime engines, and data analytics tasks), 3x the memory bandwidth (it offers 1.2 TB per second for its LPDDR5x memory), and 2x the efficiency, the company said.
An agentic AI workload that involves generating and running code will need to create a sandbox environment. That, along with other various other tasks, is best suited for a general-purpose CPU with very high single-threaded performance, such as Vera, according to Nvidia.
For example, Vera will be tasked with spinning up Linux instances, running interpreters to execute and compile Python code. The effectiveness of that generated code needs to be monitored to determine whether changes are needed, which is another workload where general purpose CPUs will shine. SQL queries may also need to be executed to grab structured data out of a database.
It’s all about matching the software workloads to the appropriate hardware to keep everything running as quickly and as efficiently as possible, said Ian Buck, Nvidia’s vice president and general manager of hyperscale and HPC.
“This might be a $30-billion, gigawatt data center [full] of GPUs. I’m not going to skimp on the CPU side and have this [GPU] sit idle or have the potential of that model come up short because I couldn’t run the compilation too long and I had to cut it off and drop that data on the floor,” he said.

“The world…needs a lot of CPUs,” Buck continued. “For training these models, they need fast CPUs in order to make sure that they get the best possible data back to the GPU and never let the GPU stall out. And then finally AI, when you actually deploy it after you’re done training, it’s not just the AI model…They call tools all over the place.”
Groq LPU
The Rubin GPU is a powerhouse of a machine, with each chip providing 50 petaflops of NVFP4 compute for AI inference. Combining Rubin with the Vera CPU in the NVL72 system creates an even better system that is tough to beat, Huang said during his keynote.
“However, if you extend it way out here…if you wanted to have services that deliver not 400 tokens per second, but a thousand tokens per second, all of a sudden NVLink72 runs out of steam and you simply can’t get there,” Huang said. “We just don’t have enough bandwidth. And so this is where Groq comes in.”
Accelerating the decode phase is why Nvidia paid $20 billion to license the Groq intellectual property and hire the Groq engineers in December 2025. Each Groq 3 LPU has only 500 MB of SRAM, which is much less memory than the Rubin GPU. But Groq LPUs feature 150TB per second of memory bandwidth, which is much more than Rubin’s 22TBps. With 256 Groq LPUs in an LPX rack, the total memory bandwidth jumps to an eye-watering 40 PBps of SRAM memory bandwidth, which is enough to power AI inference workloads with large context windows.
As Nvidia shared last week, the combination of a Groq 3 LPX rack with a Rubin NVL72 system will allow customers to generate a million tokens for $45 on a 1 trillion GPT model with a 400k context window, which is 35x more tokens than Rubin NVL72 could generate by itself.
Optimizing Decode at Scale
According to Buck, about one quarter of the computing demand in AI inference is the prefill stage, which can be handled effectively and efficiently with Vera Rubin (VR) superchips, while about three quarters is the decode stage, which works best with a combination of VR and LPX.
“Prefill is just step one, how quickly can you get to your first token,” Buck said in the press briefing at GTC. “After you’ve done that, those prefill. GPUs or CPXs or whatever you’re using to prefill, it doesn’t matter. Your token rate is all about the number of processors you’re using to generate every token after that. So it’s not a CPX thing. If you just did LPX, you would need a lot of chips because of all of that state, all that memory, all that context.
“By combining the LPX rack with VR rack, we cannot need all that,” he continued. “[LPX] is 7x faster memory bandwidth than HBM. That lets the little experts, the FFMs [feed forward networks]…we can run them here. The whole rest of the model, we can run all the … attention math, all the rest of the model can operate here [on the VR rack] so that we don’t need a dozen racks of LPX. We can deliver all that kind of performance with just two racks of LPX and one rack of VR.”
The result of that architecture is an AI factory that can deliver tokens at the rate of 1,000 per second, which we referenced earlier. This is the future that Nvidia is building
“Everything that we’ve optimized here in order to serve models can do that with high throughput, low-cost inference king economics,” Buck said. “We can bring down the cost of that of that volume of what the AI that market is today.”
If you want to read more stories like this and stay ahead of the curve in data and AI, subscribe to BigDataWire and follow us on LinkedIn. We deliver the insights, reporting, and breakthroughs that define the next era of technology.
This article first appeared on our www.hpcwire.com
The post Nvidia’s Shift from GPUs and AI ‘Inference King’ Economics appeared first on BigDATAwire.
Go to Source
Author: Alex Woodie