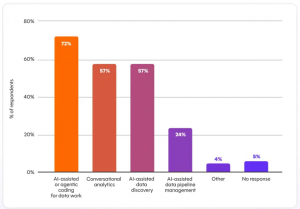
According to the State of Analytics Engineering 2026, the modern data stack is scaling fast, but unevenly. It is also growing faster than the trust and governance mechanisms designed to support it. AI is no longer experimental. It is embedded. 72% of teams now prioritize AI-assisted coding, and more than 77% of leaders are already using it to drive productivity gains. What used to be exploratory is now operational, and as a result that is accelerating how data systems are built and deployed.
The report reveals that the pressure is showing up across the system. 57% of organizations report increased warehouse and compute spend, compared to just 36% reporting team budget growth, creating a widening gap between infrastructure demand and human capacity. Data pipelines are running more frequently, shifting toward continuous execution, while the cost of moving and processing data is rising alongside scale. This is not just growth. It is sustained acceleration but without proportional reinforcement.
Data quality remains the most frequently reported challenge, while 41% of teams still report ambiguous data ownership and 36% cite data literacy gaps among stakeholders. At the same time, 71% of respondents are concerned about incorrect or hallucinated data reaching stakeholders, reflecting a growing risk as AI-generated outputs expand. The pattern is clear – systems are scaling, but the foundational issues are not going away.
Would pouring in resources help? According to dbt Labs, they do not fix system-level bottlenecks. As pipelines scale in size, speed, and frequency, the analytics stack begins to take on the characteristics of a distributed compute system. This is where throughput, reliability, and orchestration matter as much as the data itself.
(Source: dbt Labs 2026 State of Analytics Engineering Report)
“There’s a real tension between moving fast and building trust and you can’t optimize for both without intention,” says Pooja Crahen, Senior Manager of Analytics Engineering at Okta. “That’s where discipline in modeling, validation, and ownership becomes a requirement, not a best practice.”
That tension shows up directly in how data systems are evolving. Teams are accelerating development using AI, but investment is uneven across the pipeline. While 72% prioritize AI-assisted coding, only 24% prioritize AI-assisted pipeline management, including testing, observability, and quality controls. The imbalance is structural. Acceleration is outpacing stabilization.
“As we scale, our foundations must be as robust as our ambitions,” says Jeremy Chia, Board Member at Soap Cycling Singapore. “Data quality and trust remain fundamental to data as a product. This is where analytics engineers are best positioned to add value.”
The idea of data as a product depends on those foundations. It requires ownership, consistency, and clear definitions across systems. But the report shows that ambiguous ownership remains unchanged year over year at 41%, and trust, while improving as a perception, is becoming a strategic expectation rather than a solved problem. Fewer teams now cite lack of trust as an operational issue (33% to 24% YoY), but more are expected to deliver reliable outputs at scale. That shift increases the cost of failure.
“2026 is the year of context,” says Pip Sidaway, Senior Manager of Data Products and Governance at nib. “Context is information—and for analytics, that’s metadata. It’s the descriptions and names that give meaning to data for both humans and AI, along with the specific business context, including documented standards for how we do things.”
Context is becoming an operational requirement. As pipelines scale and AI systems consume more data, metadata becomes the layer that enforces meaning and consistency. Without it, data may still move through the system, but its reliability degrades. Outputs may be faster but they become harder to trust and validate.

(Source: dbt Labs 2026 State of Analytics Engineering Report)
The report points to a broader shift in how performance is defined. The importance of trust has risen from 66% to 83% year over year, while speed has increased from 50% to 71%, signaling a new expectation and it is not enough to deliver data quickly. It must also be dependable at scale. That combination is difficult to sustain without stronger systems underneath.
What emerges is a different kind of data environment. Pipelines are continuous and the outputs are increasingly automated. Failures are less visible but more consequential. This means that instead of broken dashboards, teams face systemic issues such as inconsistent data and delayed pipelines.
The report highlights that the core challenge is no longer building data pipelines. It is operating them under sustained load. As data volumes grow and workflows become more complex, the ability to maintain trust across the system becomes the defining factor. More data, more tools, and more compute do not solve that problem on their own. Dbt Labs emphasizes that the analytics stack is evolving into infrastructure. Its success will depend on how well it can scale trust alongside output, without breaking under pressure.
The report is based on 363 survey responses from data practioners and leaders across industries. The respondents include 73% practioners, while 27% serve as management or executive roles overseeing data teams.
If you want to read more stories like this and stay ahead of the curve in data and AI, subscribe to BigDataWire and follow us on LinkedIn. We deliver the insights, reporting, and breakthroughs that define the next era of technology.
The post dbt Labs Report: 72% of Data Teams Use AI. 71% Fear Bad Data. Data Systems Can’t Keep Up appeared first on BigDATAwire.
Go to Source
Author: Ali Azhar